Polluting the Well: How AI is Quietly Poisoning the Internet
AI-generated content is flooding the internet — not with insight, but with recycled noise. From SEO sludge to synthetic “expertise,” we’re poisoning the sources we once trusted. Can we still find clean water in a digital world built on mirrors?

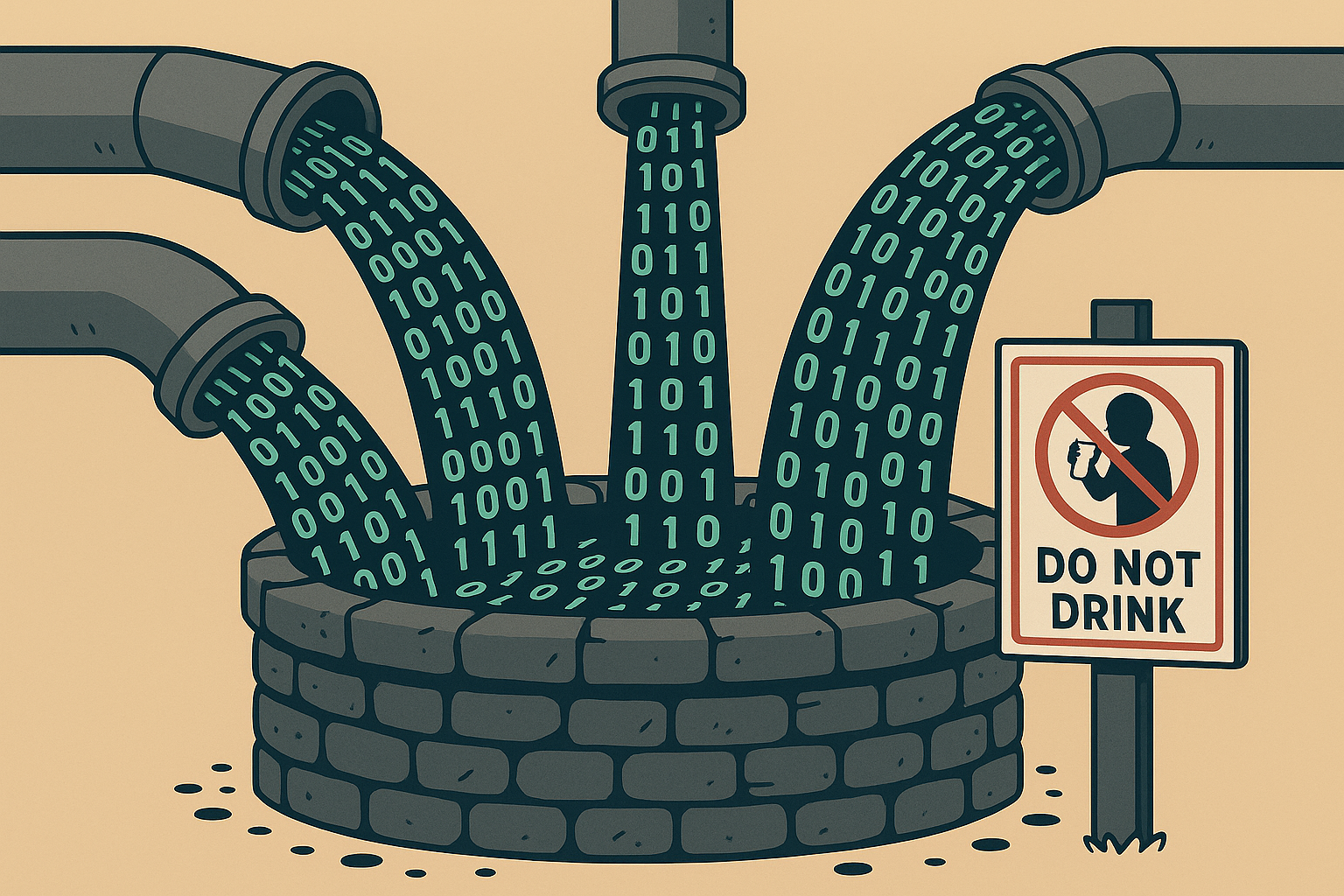
As generative AI floods the digital commons with synthetic content, the internet's most trusted knowledge wells are being poisoned. From StackOverflow to Goodreads, what once felt like an ecosystem of human insight is increasingly becoming a landfill of regurgitated nonsense. In this opinion piece, we examine the slow corrosion of digital trust, the self-consuming loop of AI training on AI, and what it might take to reclaim our information commons.
A decade ago, if you wanted a programming answer, you went to StackOverflow. Book reviews? Goodreads. A quirky niche recipe or home remedy? Blogspot or Reddit. It wasn’t always perfect, but there was a sense of voice, of authorship. Someone had been there before you, and you could trace the fingerprints.
Today, many of these wells are poisoned. Not dramatically. Not overnight. But bit by bit, post by post, a thin layer of algorithmic slime coats the once-trustworthy surfaces of the internet. And it’s spreading.
The Synthetic Flood
AI-generated content isn’t just overwhelming in volume - it’s indistinguishable, unaccountable, and often wrong. Platforms like Medium and Amazon are inundated with ghostwritten sludge: SEO-churned non-books with clickbait covers, written by no one, reviewed by bots, and bought by accident.
StackOverflow, once the gold standard for technical help, had to ban ChatGPT answers because they were so frequently wrong but confidently phrased. Meanwhile, Goodreads is filling with AI-written summaries and fake reviews, drowning genuine voices in a sea of templated mediocrity.
Even Google Search has gotten worse. Despite their 2023 Helpful Content Update, results often surface AI-written articles, scraped advice, or circular references to other low-quality AI content. Reddit threads from 2011 routinely offer more value than the top five results from 2025.
The Feedback Loop Has Started
AI is now being trained on data polluted by previous generations of AI. A 2023 paper from Stanford showed that when synthetic data dominates training corpora, models become increasingly erratic and less useful. It’s like making a photocopy of a photocopy of a photocopy - eventually, it’s all noise.
As Gary Marcus warned, “We are creating models that are learning from shadows of shadows.” The danger isn’t that the internet becomes unusable overnight - it’s that it becomes subtly untrustworthy, and we stop noticing.
Why This Is Hard to See
The average reader can’t spot a synthetic blog post from a human one. AI doesn’t always hallucinate. It just generalizes poorly, glosses over nuance, and never pushes back. It doesn’t care, and that’s the point.
Emily Bender, co-author of the landmark “Stochastic Parrots” paper, put it bluntly: “These systems don’t understand the world. They’re just regurgitating patterns.” And yet we’re training them on themselves, confident that scale will fix what insight cannot.
The Human Cost
There’s something deeply chilling about the erosion of trust in collective knowledge. When every book summary is ghostwritten by a bot, every recipe post includes fictitious anecdotes, and every forum reply sounds the same, the human element is erased. And with it, marginal voices. Indigenous stories, minority dialects, non-Western epistemologies—are pushed to the periphery or synthesized out of existence.
Timnit Gebru has long argued that uncritical AI deployment risks amplifying systemic bias. Now it’s clear: it doesn’t just amplify bias. It homogenizes experience until all content is safe, bland, and culturally dead.
What Now?
We can’t unring the bell, but we can choose how we live with it. Some suggestions:
- Demand provenance - Tools like Perplexity and Brave Search now cite sources. Use them.
- Support human-first platforms - Subscribe to newsletters, blogs, and creators who sign their names.
- Slow down AI hype - Not every startup needs an LLM. Sometimes, a forum and a FAQ will do.
- Educate for critical literacy - In schools, we should be teaching students to recognize synthetic voice, question sources, and value why something was said, not just what.
This isn’t about AI doom. It’s about defending the commons.
I’ve felt this shift personally. Whether I’m looking for a solution on a Linux forum, browsing reviews for a new hiking pack, or even reading educational material, there’s a creeping sense of déjà vu. Like everything’s being written by the same bored intern who’s never left the house.
But it’s not an intern. It’s a language model, running 24/7, outpacing our ability to contribute or critique. As a teacher, a writer, and a participant in the open internet, that bothers me.
Yet I’m hopeful. The same tools that polluted the well can help purify it if we’re careful. If we value human authorship, amplify diverse voices, and stay alert to the slippery convenience of synthetic thought.
The well isn’t poisoned beyond saving. But we do need to actively guard it.
That means more than just critiquing AI outputs. It means building and reinforcing human-centered infrastructure: open-source wikis curated by actual experts, forums where moderation still matters, school curriculums that teach source evaluation as seriously as numeracy. It means pushing back against platforms that reward speed over substance, and algorithms that optimise for engagement at the cost of insight.
We need to create small, intentional spaces like blogs, Discord communities, classroom projects, federated networks that resist scale for the sake of meaning. We need to support toolmakers who bake in attribution and transparency by design, not as an afterthought. And when we use AI, we should use it in service of thinking, not as a replacement for it.
This isn’t about halting progress. It’s about deciding what kind of progress we want. We can automate output, but we can’t automate trust. That part’s still up to us.